Enginyeria de Costos
Buscant el desperdici mínim a AWS i Kubernetes
Full Stack Valles - 27 de maig del 2025
Què tractarem avui
- Recursos orfes
- Right-sizing
- AWS: RDS, ElastiCache, etc
- Kubernetes: Pods
- Computació
- Modes de compra
- Escalat Kubernetes (Karpenter)
- Xarxa
- Trànsit entre AZ
- Sortida Internet
- VPC Endpoints
-
Casos pràctics
- Caching amb Redis
- Lambda o Beanstalk + SQS -> KEDA
- Bases de dades Multi-AZ
Recursos orfes i obsolets
"Els recursos que no s'utilitzen però que encara generen costos."
- EBS volumes no adjuntats
- EIPs no assignades
- Load Balancers buits
- Snapshots antics
- NAT Gateways sense enrutar
- Suport estès (RDS, EKS, ElastiCache)
- En definitiva, tot allò que no s'està utilitzant
Right-sizing
Ajustar els recursos al que realment necessites
- Sobreprovisionament → Diners llençats
- Subprovisionament → Problemes de rendiment
- L'objectiu: El punt òptim
- El veurem en dos contextos: AWS i Kubernetes
Right-sizing
Right-sizing: AWS
RDS, ElastiCache, OpenSearch...
- Utilització real vs. capacitat
- Controla CPU, memòria, IOPS
- Valida la necessitat i mida dels clusters
- Cada entorn el que necessita (pro, stg, dev)
Right-sizing
Right-sizing: Kubernetes
- Requests vs Limits: la diferència costa diners
- Requests massa alts → Pagues per CPU/memòria no utilitzada
- Requests massa baixos → Throttling o OOMKilled
- HPA: Escala automàticament segons la demanda real
- Node autoscaling: Ajusta el nombre de nodes al cluster
Computació
Computació: Tipus d'instància
On-Demand vs Spot vs Savings Plans
| Tipus | Estalvi | Ús |
|---|---|---|
| On-Demand | 0% | Producció crítica |
| Spot | 70-90% | Workloads tolerants a interrupcions |
| Savings Plans | 50-70% | Ús consistent (1-3 anys) |
Computació
Computació: Escalar Kubernetes amb Karpenter
- Provisiona nodes basat els recursos pendents d'assignar
- Consolidació automàtica de nodes quan no hi ha demanda
- Suporta Spot Instances nativament (vs Cluster Autoscaler)
Xarxa
Xarxa: on els costos s'amaguen
| Concepte | Cost | Recomanació |
|---|---|---|
| Entre Availability Zones | 0.01 USD/GB (cada direcció) | Mantén serveis i dades a la mateixa AZ |
| NAT Gateway | 0.045 USD/hora + 0.045 USD/GB | Un per AZ, agrupa sortida, usa S3 Gateway Endpoint |
| VPC Endpoints | 0.01 USD/GB (Interface) | Evita NAT/Internet per APIs d'AWS (S3 gratuït!) |
Regla d'or: Minimitza els salts entre AZ i evita la sortida a Internet quan pugis accedir via privat
Xarxa
Xarxa: Arquitectura Multi-AZ
Lectures locals = 0 trànsit entre AZ
digraph G {
rankdir=LR;
node [shape=box, style=rounded, fontname="Arial"];
edge [fontname="Arial", fontsize=10];
pod_az_a [label="Pod AZ A", fillcolor="#6cf", style="rounded,filled"];
pod_az_b [label="Pod AZ B", fillcolor="#6cf", style="rounded,filled"];
primary [label="Primary", fillcolor="#f96", style="rounded,filled"];
replica_az_a [label="Replica AZ A", fillcolor="#9f9", style="rounded,filled"];
replica_az_b [label="Replica AZ B", fillcolor="#9f9", style="rounded,filled"];
pod_az_a -> primary [label="write"];
pod_az_b -> primary [label="write"];
primary -> replica_az_a [label="sync", style=dashed];
primary -> replica_az_b [label="sync", style=dashed];
pod_az_a -> replica_az_a [label="read"];
pod_az_b -> replica_az_b [label="read"];
}
- WRITE: Tots els pods escriuen al Primary (alguns creuen AZs)
- SYNC: Primary replica automàticament a les altres AZ
- READ: Cada pod llegeix de la rèplica de la seva AZ (gratuït!)
Casos pràctics
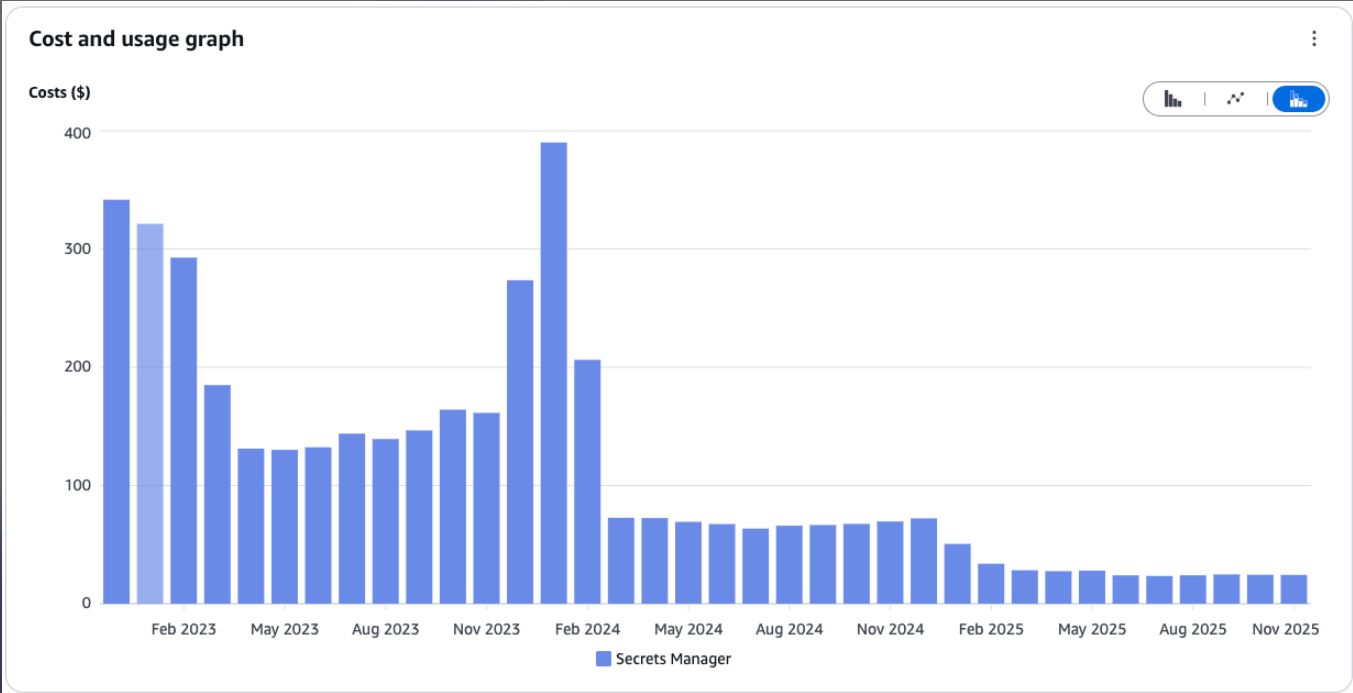
~93% estalvi · ~298 USD/mes
Caching
Redueix càrrega, redueix cost
- Redis / ElastiCache
- Cacheja respostes d'APIs externes
- Cacheja resultats de BBDD
- Sessions d'usuari
- Patró Cache-Aside
- 1. Mira cache
- 2. Si no hi és, va a origen
- 3. Desa a cache per propera vegada
- Estalvi indirecte:
- Menys càrrega a BBDD = pots fer right-sizing
- Menys crides a API = estalvi de sortida
Casos pràctics
~70% estalvi · ~2.225 USD/mes
Patró Lambda o Beanstalk + SQS
Una combinació perillosa per al cost
- Abans: Lambda + SQS → ~3.200 USD/mes
- Després: KEDA + Kubernetes → ~975 USD/mes
- Resultat: 70% menys de cost → ~2.225 USD/mes estalviats

Casos pràctics
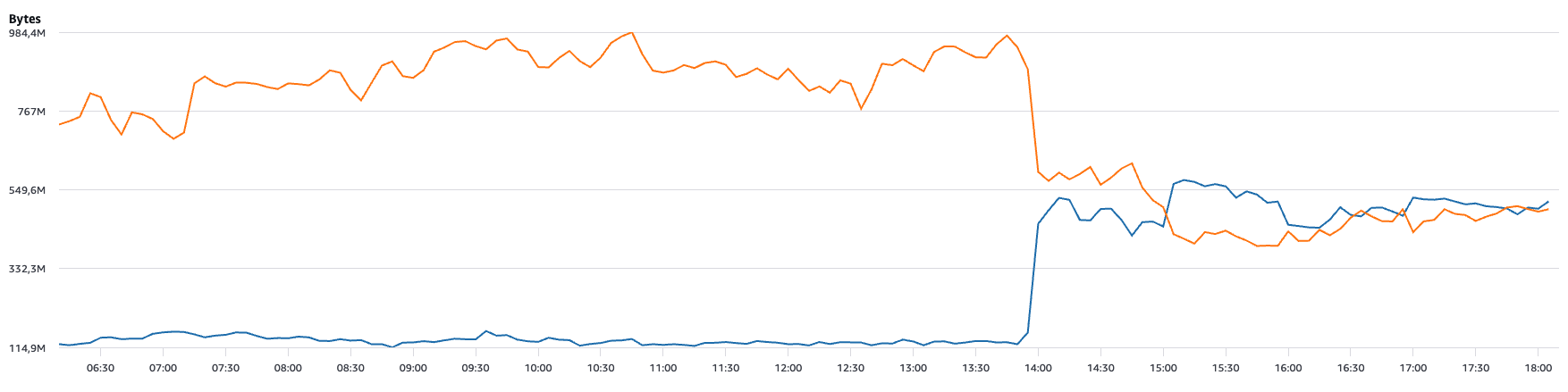
~41% estalvi · ~59 USD/mes
Bases de dades Multi-AZ
Lectures locals = 0 trànsit entre AZ
- Abans: totes les lectures al Primary → ~850 MB/5min entre AZs
- Després: lectures a la rèplica local → ~500 MB/5min (-350 MB/5min)
- Resultat: 41% menys de trànsit inter-AZ → ~59 USD/mes estalviats
Conclusions
- La enginyeria de costos és continuada, no un esdeveniment
- Monitoritza, mesura, optimitza
- Cultura FinOps: responsabilitat compartida
- Valorar la resiliència de la infraestructura i les bones pràctiques vs els costos
Gràcies!
Preguntes?